




《续》
3.3.2 APTPPA 算法的挖掘过程
经典的Apriori算法在执行过程中会产生大量的中间项集,必须多次扫描数据库,需要很多辅助的空间结构,甚至要求数据也得是二值逻辑的。本文采用的APTPPA算法在压缩数据的同时保证原始数据集合的基本状态,使其在多值和倾斜数据以及负关联规则的挖据中比其余同类算法更加准确。APTPPA算法的关键步骤包括关联路径树生成、频繁项目集挖掘和找寻最大频繁项集三步。
(1) 关联路径树的生成
将事务数据库D中每个数据项im进行逻辑化处理后会致使项数大量增加,导致算法维灾难。减少项数的方法之一就是标号化数据项值,项的每种类别值都用标号vn表示。以实验的1000组15项肉鸡超限异常数据为例,标号化后的事务数据集D如下表所示。
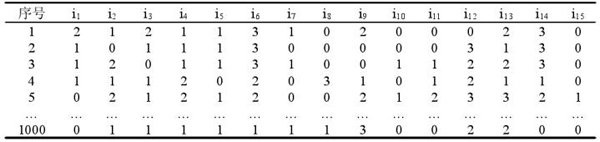
表3-2 数据集D标号化处理结果
数据集D在逻辑化、标号化处理后,各项值域大大减小,其内部会存在较多相同的事务数据。此时可由集合D构建基于表的关联路径树,树中所有的路径表示集合D中全部可能存在的事务记录,树中的节点数字则表示某种记录类型存在的总数。关联路径树见图3-4。
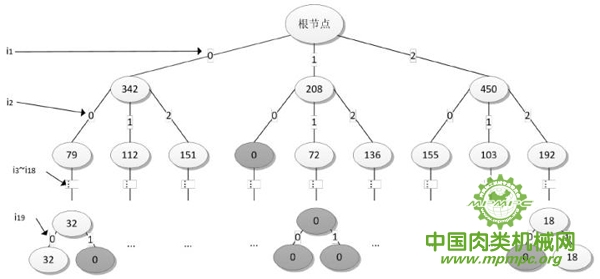
图3-4 基于数据集D生成的关联路径树
图中,顶层根节点到下层节点的路径定义为i1的值,第一层节点再往下层节点的路径定义为i2的值,以此类推。i1~i19对应着数据集D中的每一列事务项。叶子节点计数为零时,表明该条事务记录从未出现在原始数据集D中,在生成路径表时这些事务路径需要被剔除。经过上述关联路径树的事务合并计数、删除冗余后,可以形成一个无重记录的数据集合D’,并得到基于集合D’的关联路径表,见表3-3。

表3-3基于数据集D得到的关联路径表
由于去除了冗余的数据项,所以任何一条事务数据Ti都包含着项目集的一种取值并构成最大项集,其支持度就是事务数据的计数counti。数据集D到这里已经进行了大幅的压缩简化,使事务在接下来的组合计数算法中可以尽量一次性的转存到存储器中。
以上描述中算法的执行过程如下:
input D & p;
for each Ti∈T D then
for each im∈T then
离散化值im,标号为Vn;
path = path Vn;
path按p进制转化为整型,排列、计数并存入关联路径表;
end for
end for
output Map结构的关联路径表;
其中p为离散化事务项的最大质数标号;当path长度过大时,可对其进行分段,以此提高效率。
(2) 频繁项目集的挖掘
根据Apriori特性,可以通过模式指导在关联路径表上找寻出频繁项目集。所谓模式此处即形如“xxooxxxxo”的某种排列组合,事务项“x”位处的项值会被忽略,再把“o”位处项值等同的数据项计数并算总和,此时的事务项就是该模式下的频繁项集,而这个和就是项集的计数。就非倾斜数据而言,在“o”增长的同时,此模式的事务计数锐减,从而有效收敛。对于倾斜数据,事务计数原本就大于支持度阀值,模式计数退化。此时若需保证算法的快速收敛,得将包含全部项的频繁项目集计数归零,再进行下一轮模式计数。在此期间还可以通过设定的最小支持度阀值对项集组合进行直接的剪枝操作。以实验中1000组15项肉鸡超限异常数据为例,找到频繁项集见表3-4。
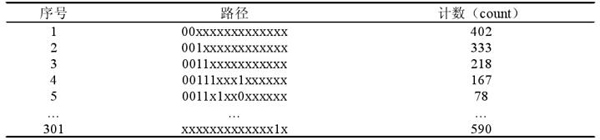
表3-4 挖掘出的频繁项集
按模式指导求频繁项集的这种计算形式为相关算法的并行递归提供了良好的支持。m个项有m个1-"o"模式(k-"o"模式是指包含频繁k项集的模式)的初始项目集。此处的并行递归就是在关联路径树上把1-"o"模式作为起始条件递归生成其它模式的方法。单线程时,全部模式按1-"o"标准产成步骤依次递归完成。多线程时,每个线程分配一个1-"o"模式,能大大提高递归速度。最后,当事务数据项计数不满足递归算法的限值时,算法结束并有效收敛。
以上描述中算法执行的过程如下:
扫描关联路径表,将数据项计数counti>minsup的事务Ti纳入频繁项目集F;
生成模式串pattern_string,并令k = 1;
for each 1-“o”pattern_string then
分配线程,在线程threadi上调用recu_process( k, k+1, pattern_string );
k = k + 1;
end for
上述步骤中,不同模式匹配各自的前缀簇,然后递归增加互不干扰,这个特性满足了多线程并行计算的基本要求。
recu_process(start, pos, pattern_string)定义如下:
for i from pos to m的后缀路径then
for each Ti∈T D' then
if path == pattern_string.substring(start, pos) then
pos项的标号Vn进行长度为p的hash计算;
end if
end for
for each hash[j]∈hash表then
if hash[j]>minsup then
增量组合pattern_string;
F.put(pattern_string, hash[j]);
recu_process(start, i+1, m, pattern_string);
end if
end for
end for
其中start表示后缀的开始点,pos表示后缀的迭代点,m表示项目集的规模。pattern_string一方面指导了递归过程,另一方面也表示了最终的频繁项集。
(3) 寻找最大频繁项集
为了使挖掘出来的结果都更有意义,就有必要在挖掘过程中剔除相似的关联规则,防止重复规则的出现。寻找最大频繁项目集是剔除相似规则的一条途径。就APTPPA算法而言即在模式指导树上取路径a和其它任意路径b比较,当a为“o”的位包含在b中时,把b 的值赋给a,如此反复直到不能发现路径b为止。以实验的1000组15项肉鸡超限异常数据为例,找到的最大频繁项集如表3-5所示。
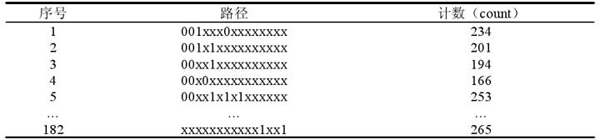
表3-5最大频繁项集
3.3.3 预警模型的处理流程
肉鸡产品质量安全预警模型处理流程的步骤分成数据预处理、建立预警模型、挖掘结果检验三步。预警模型处理流程见图3-5。
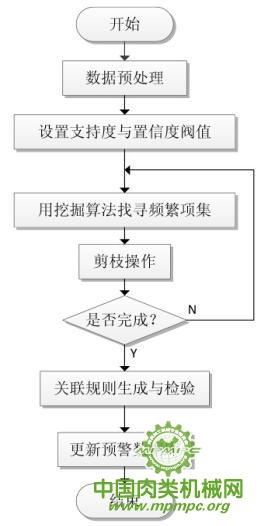
图3-5肉鸡产品质量安全预警模型处理流程
数据预处理事先会将采集到的异常数据做逻辑转换和分类操作。逻辑转换针对监测数据为连续值的情况,连续值数据无法进行关联规则挖掘,因此要事先转换成逻辑值。分类是保证预警模型预警等级准确度的前提,不同分类的异常数据后续的处理方式也不同。异常数据依据食品安全预警事件特征提取形式可分为常规异常和超限异常。
超限异常指的是结合各项指标集合找到的存在影响食品质量安全状况的结果,它们是极其容易导致食品质量安全问题的因素。
常规异常包括不规范、分布和趋势异常三种。
(1) 不规范异常是指未按标准方式获得,具有不可信性的数据。
(2) 分布异常通过区域的分布统计发现问题,将地区划分为n个区域,各区域内超限异常总数为ki(i≤n),不同地域监测总数是li(i≤n),异常情况数量均值Wi计算式子为:
当Wi高于预置阀值的时候,进行预警。
(3) 趋势异常可从过往记录中分析得知,将历史数据划分为n个时间段,第i个时间区段发生的异常数目为ui,n个时间区段发生的异常均值为u*,i*为n个时间段的中值,趋势异常系数r计算公式为:
趋势异常系数r与显著性指标p关系见表3-6。
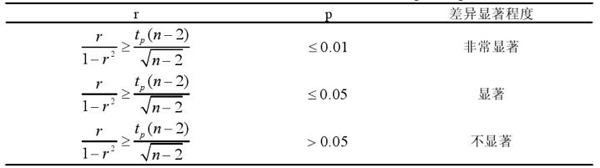
表3-6趋势异常系数与显著性指标关系
其中p为不等式满足t分布时查询到的值,当p低于相应的预置阀值时,进行预警。
建立预警模型即是将经过预处理的异常数据,通过APTPPA算法进行数据挖掘,找到频繁项集,提取关联规则的过程。这个过程中随着算法模式匹配的深入当项集计数锐减时,便可使用预先设置的最小支持度阀值对数据集合进行剪枝操作,以达到快速收敛的效果。
挖掘结果检验就是把新生成的预警规则与原有规则库和实际预警效果进行对比和分析,看是否存在出入。如果原有库中不存在该条规则,并且印证规则具有实际预警效果时,则将本次挖掘出的规则更新到现有规则库中。
3.3.4 实验与分析
抽取河北正先食品有限公司肉鸡产品质量可追溯系统溯源数据库中的1000组15项历史超限异常数据,实验验证了预警模型的有效性。同时将分别采用APTPPA与Apriori算法的肉鸡预警模型进行实验对比,验证了APTPPA算法应用在食品安全预警领域的高效性。
借鉴生猪产业链的食品安全预警关联规则较优挖掘阀值,将实验参数设置如下:最小支持度阀值= 0.3;最小置信度阀值= 0.8;最大规则数= 500。实验后从中选取的3条报警记录如表3-7所示。

表3-7 APTPPA算法挖掘出的最大关联规则
将上述生成的强关联规则与历史超限异常数据进行对比与校验,匹配度高达百分之八十,超限指标的预警也较为准确,表明了本文预警模型的有效性。由以上最大关联规则分析出肉鸡生产、加工过程中存在的部分安全规则有:肉鸡养殖环境中的氨气水平、可吸入颗粒物同时超标时,会导致鸡仔活动减少,需要对栋舍进行清理;养殖用水中氯化物、硝酸盐同时超标时,会引起鸡仔的食量下降,需要对水质进行改良;屠宰车间中氧气浓度、氨气水平同时超标时,加工设备中会滋生较多的细菌,需要对车床进行消毒。
根据挖掘结果,得到最大频繁项集计算长度k以及实际长度k'与最小支持度阀值minsup 的关系如图3-6所示。
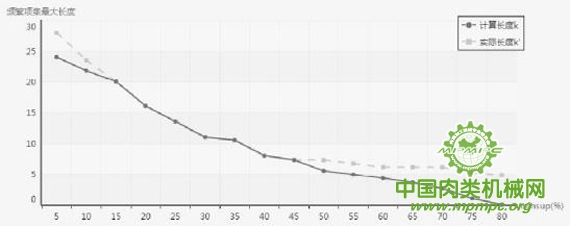
图3-6最大频繁项集计算长度和实际长度与最小支持度阀值的关系
由上图可知最大频繁项集的实际最大长度大于等于计算长度,且计算值k又只与项的最大取值及最小支持度存在关联关系,项集的多少并不影响算法的效率。因此,即使 APTPPA算法在面对较多的历史数据进行挖掘分析时,也能够从容的保持算法效率和收敛性。算法本身支持多线程并行运行,其在不同数据集大小的情况下单线程与多线程挖掘速度对比如图3-7所示。

图3-7单线程与多线程挖掘速度对比
由上图可知在数据集增大的同时,挖掘分析的速度迅速减慢。适配了多线程程序运行方式的算法在数据集达到一定规模后,所消耗时间的增长率反而在减小。这里多线程的线程数在启动挖掘分析程序时决定,主线程传入参数interval=2000、limit=10,表示每增加2000组数据就新启一个线程安排运算,最多允许启用10个线程。
为了验证不同算法的预警效率,使用河北正先食品有限公司提供的1000组15项超标异常数据分别检测对比APTPPA和Apriori算法规则挖掘的效果,在保证预设参数一致的状态下,两种算法的挖掘效果如图3-8所示。

图3-8 APTPPA与Apriori算法的速度和精度对比
由上图可知相同的实验参数覆盖下,APTPPA算法产生的预警规则少且精炼,算法执行速率也较快。Apriori算法无法充分顾及食品安全预警规则的特征,产生冗余和不符现实情况的结果也较多。综上所述,基于APTPPA算法的肉鸡产品质量安全预警模型在肉鸡食品信息预警时是准确且有实效的,相对原始Apriori算法关联规则挖掘的预警能力要强。
基于关联规则的肉鸡产品质量安全预警模型使用了APTPPA算法,该方法能够在海量繁杂多变的影响因素中,挖掘出导致肉鸡食品安全问题的要素,及时发现鸡仔养殖、屠宰加工等环节的隐患信息并预警,在真正做到实时监控的同时有效的减少和消除了食品安全事故。
3.4 本章小结
本章首先基于HACCP体系和有限状态机理论详细分析了肉鸡溯源系统的溯源信息结构以及溯源流程,随后重点介绍了肉鸡溯源系统中预警模块采用的基于关联规则的肉鸡产品质量安全预警模型,并通过实验分析证明了该模型在肉鸡食品安全预警中的有效性。
第4章 肉鸡产品质量可追溯系统的设计与实现
通过第三章中基于HACCP体系的溯源信息分析,为肉鸡溯源系统的溯源编码以及溯源信息数据库设计提供了依据,溯源信息流转过程的设计则完全建立在相关流程分析的基础之上,而预警模型的研究成果充分利用在了本章预警模块的设计与实现中,整个溯源平台的网络结构、功能模块设计也依托于前一章节的研究内容。
4.1 系统概要设计
4.1.1 体系架构设计
在进行系统体系架构的选型设计时,主要考虑项目本身的快速迭代化开发需求,因此需要采用相对简单,且能够保障系统稳定性、扩展性和兼容性的体系结构。肉鸡可追溯系统最终选择了Java EE架构、关系型数据库My SQL、Tomcat服务器以及Linux操作平台。肉鸡溯源系统软件体系架构见图4-1。
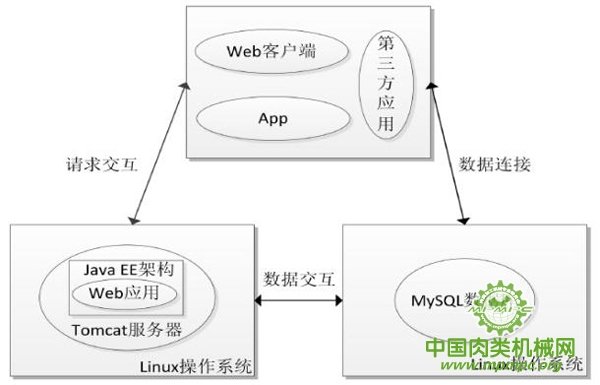
图4-1肉鸡溯源系统软件体系架构
Java EE具有部署可移植、健壮、可伸缩且安全的服务器端Java应用程序,在Java SE的基础上,它提供了Web服务、组件模型、管理和通信API,可以用来实现企业级的应用和服务。My SQL是免费开源的数据库管理系统,具有强大的社区力量维护,是一款支持多存储引擎、多操作系统、多语言API、多国编码的数据库,可以处理拥有上千万条记录的数据集,足以支持溯源系统的研发。Tomcat作为轻量级WEB服务器,以占用资源少、灵活配置与快速响应等特点被中小型系统广泛采用。而Linux则一贯以高稳定性,成为 Web部署、数据服务等首选操作系统。
4.1.2 网络结构设计
系统网络结构的设计基本上遵循低延时、高吞吐量、少干扰、多负载,兼考虑成本等因素而来。肉鸡可追溯系统的网络结构设计见图4-2。
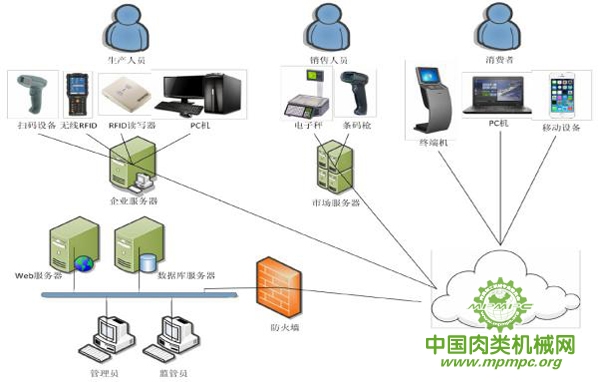
图4-2肉鸡可追溯系统网络结构
管理人员可通过内部网络,直接使用浏览器登录WEB服务器中的管理系统;消费者则需使用联网的PC机、手持移动设备或者市场中安装的自助终端来进行相关产品信息的查询;肉鸡生产企业将溯源信息保存在企业内部服务器中,再通过定期的数据同步服务把本企业的产品信息发布到数据中心;同样,肉鸡销售商则会暂时将销售数据存储在市场服务器上,待到指定时间才会把数据同步至数据中心;WEB服务器仅通过局域网即可访问数据服务器,内网与外网之间由防火墙阻隔,保障应用安全;手持设备可以直接访问WEB服务器中的某些基本数据,其WEB应用已经开放了相关的 API,供移动设备的信息查询。
4.1.3 功能模块设计
结合用户需求以及系统分析的结果将关键生产步骤的技术指标作为跟踪溯源的重要信息。对于养殖企业,把雏鸡来源、养殖环境、添加剂、饲料、兽药、免疫、储运等作为关键控制点的溯源信息。对于屠宰企业,选取加工环境、检验、工具消毒、等工序收集信息。将销售企业中的交易对象、成品来源、产品去向、储运等环节纳入追溯范畴。同时,构建宣传公示平台直面消费者和广大网民的监督查询。另外,预警功能模块则可以减小食品安全突发事故的风险。肉鸡溯源系统的主要功能模块(部分简略)见图4-3。
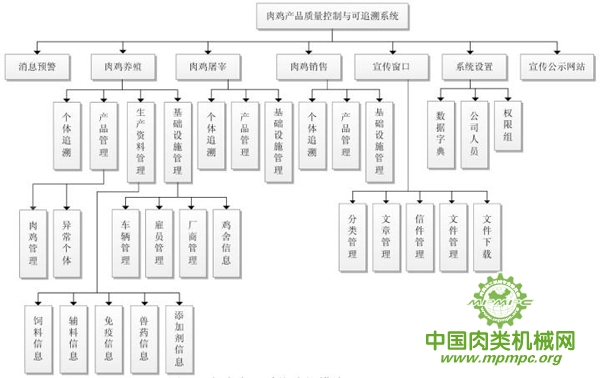
图4-3肉鸡溯源系统功能模块
由上图可知,肉鸡溯源系统总共包含七大模块。消息预警模块是相对独立的程序单元,也是本系统的一大特点。肉鸡养殖、屠宰和销售模块是三类企业溯源信息管理维护的入口,三个模块的设计结构大体相似,大致包含了内部个体追溯、产品管理、生产资料管理以及基础设施管理这几个部分。宣传窗口是系统后台对于宣传公示网站模块的维护端,而宣传公示网站则是互联网公共服务的展示窗口。系统设置是整个溯源系统的管理控制中心。



